|
|
|
      |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
La Iniciativa de Informática Estratégica Acelerada (ASCI) es un ambicioso proyecto del Departamento de Energía de EEUU para analizar asuntos clave relacionados con la seguridad nacional a través de sofisticados sistemas de simulación. El programa ASCI , que debe terminar en 2006, se ha propuesto desde el principio llegar a los 30 billones de operaciones por segundo a mediados de 2001. Y hacia el año 2004 prevé alcanzar los 100 billones. Esta capacidad de cálculo es extraordinaria. A modo de comparación, si una persona se pusiese a realizar operaciones con una calculadora al ritmo sostenido de una por segundo, tardaría 10 millones de años en hacer las mismas operaciones en que ASCI emplea un solo segundo. Otro ejemplo es que si los 6.000 millones de personas que pueblan ahora la Tierra pidieran al mismo tiempo una página de Internet, el superordenador tardaría menos de un minuto en servir todas las páginas. Suponiendo, claro está, que esta conexión masiva fuera posible hacerla. Para llevar a cabo este proyecto, el Gobierno de EEUU ha elegido a IBM como socio tecnolponer en marcha el sistema ógico encargado de informpropio Ministerio de Defensa, ático más potente del mundo. Más, incluso, que los superordenadores de su instalados en el Pentágono. El sistema elegido para el proyecto ASCI está basado en la plataforma IBM RS/6000 SP. Las razones por las que se ha elegido radican fundamentalmente en su filosofía y su diseño: la arquitectura de esta plataforma, creada en 1991, asegura la escalabilidad requerida para el proyecto (capacidad de proceso medida en Teraflops) y también la capacidad de crecimiento futuro, muy por encima de cualquier otros sistema.
La Iniciativa de Computación Estratégica Acelerada (ASCI) es un esfuerzo de tres laboratorios nacionales, Lawrence Livermore National Laboratory (LLNL), Sandia National Laboratory (SNL) y Los Alamos National Laboratory (LANL), para proporcionar una computación a escala "Tera" para un modelado sofisticado usado en el Programa Administrador de Reservas. Estableciendo un consorcio de tres laboratorios para desarrollar con éxito una paralelización masiva, el programa ASCI espera la entrega de una capacidad fiable de computación de 100 trillones de cálculos por segundo en el 2004. Una novedad de los superordenadores del programa ASCI es que se construyen a base de conectar multitud de ordenadores estándar y consiguen que trabajen de modo paralelo El coste del ASCI White, 20.000 millones de pesetas, resulta tan sólo una fracción de lo que valdría si se emplearan elementos construidos a medida. El ASCI White ha costado tan sólo un 25% más que su hermano pequeño Blue Pacific, que IBM entregó al mismo centro de investigación de la Universidad de California donde se instaló el ASCI White. La potencia de cálculo de estos superordenadores se consigue a través de dos tecnologías: el proceso compartido de memoria (SMP) y el masivamente paralelo (MPP). Cada uno de los 512 ordenadores RS/6000 SP de IBM tiene 16 procesadores, que trabajan simultáneamente contra una memoria común. Todos estos ordenadores están unidos entre sí por medio de un conmutador que hace que pueda darse la comunicación en todos los sentidos, a una velocidad de 200 millones de bytes por segundo (200 MB/s). Así, se consigue la capacidad de cálculo total. Esta técnica combinada también la emplea Intel en el ASCI Red, el segundo de la lista, construido bajo el mismo programa ASCI y que utiliza microprocesadores Pentium III normales y corrientes. Pasado, presente y futuro del proyecto En julio de 1996, el laboratorio
norteamericano LLNL (Lawrence Livermore National
Laboratory) anunció la selección de IBM como
suministrador de lo que estaba destinado a ser la solución
informática más potente del mundo. El proyecto, para el
que se destinó un presupuesto de casi 200.000 millones
de pesetas, fue bautizado como ASCI ((Accelerated
Strategic Computing Initiative). El núcleo del proyecto ASCI en su primera fase es un ordenador IBM RS/6000 de 512 procesadores que gestiona una red cliente/servidor. Este sistema, que se denomina ID (Initial Delivery System), alcanza un rendimiento de 136 Gigaflops, con una memoria total de 49,1 GB y capacidad para 1,5 Terabytes. A finales de 1998 comenzó la segunda etapa del proyecto (TR, Technology Refresh), en la que IBM reemplazó el sistema actual por otro aún más potente, con niveles de rendimiento cercanos a 1 Teraflop En una tercera fase, IBM construyó y puso en marcha un sistema denominado SST (Sustained Scalable Teraflop System), con una potencia superior a los 3,2 Teraflops IBM se ha comprometido a una cuarta fase (ASCI White) donde se ha llegado, por primara vez, a una velocidad de dos dígitos de medida en Teraflops. Las claves del proyecto Desde hace años, los responsables de investigación del Laboratorio LLNL han venido realizando importantes seguimientos sobre factores relacionados con la energía. Para esta labor, los miembros del laboratorio -que reporta directamente al gobierno de los Estados Unidos- se han servido de los más sofisticados sistemas de testeo y análisis. Pero, de un tiempo a esta parte, la informática ha venido permitiendo cada vez más prestaciones de cálculo de variables, gestión de gráficos avanzados e incluso generación automática de informes para el apoyo a la toma de decisiones. El proyecto ASCI tiene como principal objetivo pasar de una operativa centrada en sistemas de testeo a un entorno donde sea posible simular virtualmente cualquier situación para conocer, con márgenes mínimos de error, las consecuencias de cada una de estas situaciones. A través del acuerdo suscrito entre los progenitores del proyecto e IBM, ésta última se compromete a crear sistemas capaces de gestionar todas estas actividades ahora y en el futuro, manteniendo en todo momento los niveles necesarios de potencia, capacidad de crecimiento y seguridad. ¿Porqué RS/6000 SP? El proyecto RS/6000 SP nació en 1991 con el claro objetivo de construir un sistema capaz de crecer de forma exponencial. Es por ello la plataforma idónea para un proyecto como ASCI, que precisa niveles de rendimiento que no aporta ningún sistema hoy, y la capacidad de soportar cualquier cambio en el futuro. El modelo de multiproceso simétrico proporciona la base, con múltiples procesadores que acceden a todos y cada uno de los recursos de la red. La arquitectura NUMA (non-uniform Access Memory) simplifica a su vez la complejidad del sistema SMP, al gestionar Terabytes de información desde un solo punto. Pero el sistema DMP (Distributed Message Passing) del RS/6000 SP aumenta aún más el rendimiento, ya que cada nodo (servidor) de la red tiene su propio sistema operativo, de forma que la comunicación entre nodos pasará por el espacio compartido sólo si es necesario; si no, el trasvase de datos se realizará mediante "mensajes" entre ellos, incluso páginas enteras de memoria. Pero la importancia del proyecto ASCI no se limita a lo que se consiga hoy. De hecho, no es un desarrollo a la medida de un proyecto aislado. IBM concibe su desarrollo como punto de partida hacia lo que será el modelo a seguir por los sistemas informáticos del futuro. El ordenador paralelo IBM de escala "Tera" se instaló en el año 1996 en LLNL como el segundo super-ordenador ASCI. A final del '97, una renovación técnica mejoró los nodos en cuatro formas. Blue Pacific es un hiper-cluster de 1.464 nodos IBM SP con una realización probada en 1999 a 3.9 TeraOPS (trillones de operaciones de punto flotante por segundo). El sistema proporciona 2,6 terabytes (TB) de memoria y 75 TB de disco globalmente accesible RAID. ASCI BLUE PACIFIC sobrepasa las espectativas El 22 de septiembre de 1998, la sociedad ASCI/IBM logró un hito importante en cuanto al Blue-Pacific nada menos que tres meses antes del plazo. Blue Pacific logró una actuación récord mundial haciendo funcionar el hito hidrodinámico del Método Parabólico de piezas simplificadas (sPPM) a 1.2 TeraOPS. Además, se estableció un segundo récord de funcionamiento sPPM con 70.8 billones de zonas. Este sorprendente doble logro representó un salto cuantitativo en la mejora de la computación a escala superior. Dentro del sistema hipergrupo de 1,464 nodos de Blue Pacific, 432 nodos Silver, de 2.5 gigabites (GB) de memoria SDRAM y 18 GB de disco local. 1.032 nodos Silver adicionales tienen 1.5 GB de memoria SDRAM y 9 GB de disco local. Esto crea una arquitectura muy flexible para la ejecución de aplicaciones en 3D de media escala a extremadamente grandes. La fuente Blue Pacific opera en un ambiente clasificado que apoya el Programa de Administración de lo Almacenado. Caracteristicas del sistema ASCI Blue-Pacific
Para accesos no clasificados, existe un sistsema de
344 nodos Silver en una red de trabajo no clasificado,
que permite a los científicos de DOE beneficiarse de una
investigación de colaboración con sus colegas en la
industria y en las academias. Este sistema abierto tiene
su punto más alto en 892 gigaOPS, 504 GB de memoria
SDRAM y 18 TB de disco RAID accesible de un modo global. Arquitectura Hardware del Blue-Pacific La arquitectura del sistema Blue-Pacific es un hipergrupo SP (Paralelo escalable) de IBM de acceso de memoria uniforme SMPs (UMA). Cada SMP de cuatro direcciones es un ordenador independiente, completado con un sistema operativo, discos locales (para intercambio y espacio temporal del usuario) y para una red de trabajo a baja velocidad (Base 100 T Ethernet y otros como FDDI o HIPPI-800 como opciones). Estos nodos pueden tener un máximo de 3 GB de alta velocidad, baja latencia de memoria SDRAM. Los cuatro procesadores de IBM potencia PC 604e funcionan a 332 megahertzios (MHz) y tienen capacidad para ejecutar dos instrucciones por cada ciclo de reloj. Una instrucción por ciclo de reloj puede ser el punto de flote (suma múltiple encadenada es una instrucción sencilla en el punto de flote). El procesador Power PC 604e tiene un juego asociado de cuatro direcciones de instrucción y datos 32 KB de caché L1. El frente combinado de caché 256 MB L2 también es un juego asociativo de cuatro direcciones y funciona a la velocidad del procesador.
Arquitectura de Software del Blue-Pacific Desarrollado por Intel Corporation y Sandia National Laboratories bajo los auspicios de la Iniciativa de Computación Estratégica Acelerada (ASCI) del Departmento de Energia. Manejado por Sandia para los programas de defensa del Departamento de Energía. Esta computadora, que ha sido instalada en SNL, es masivamente paralela, es MIMD. Merece la pena destacarla por varias razones. Fue la primera supercomputadora TFLOPS del mundo. I/O, memoria, nodos de computación y comunicación son escalables en grado máximo. Los interfaces standard paralelos hacen relativamente simple la conexión de aplicaciones al puerto paralelo. Este sistema utiliza dos sistemas operativos para hacer que el ordenador sea tanto familiar al usuario (UNIX) como no intrusivo para la aplicación escalable (Cougar). Y utiliza la tecnología Commercial Commodity Off The Shelf (CCOTS). Hardware El sistema ASCI TFLOPS es de memoria distribuida, MIMD, superordenador de paso de mensajes. Todos los aspectos de la arquitectura de este sistema son escalables, incluyendo la comunicación en banda ancha, memoria principal, capacidad interna de almacenamiento en disco y I/O. El superordenador TFLOPS está organizado en cuatro partes: computación, servicios, sistemas y entrada/salida. La parte de servicio proporciona un servidor escalable integrado que apoya a los usuarios interactivos, el desarrollo de la aplicación y la administración del sistema. La parte I/O sostiene un sistema de archivos escalable y servicios en red. La parte del sistema sostiene la capacidad de confianza en el sistema, la disponibilidad y el servicio en red. Finalmente la parte de Computadora contiene nodos optimizados para el trabajo en coma flotante y es donde se ejecutan las aplicaciones en paralelo. Los parámetros del sistema hardware se resumen en la Tabla. Caracteristicas del sistema ASCI RED
Software El software en el supercomputador TFLOPS es una combinación de sistemas operativos hechos a medida para tareas específicas y herramientas de programación standard para hacer que la computación sea tanto familiar al usuario como no intrusiva para la aplicación escalable. Para el programador de la aplicación, el sistema parece un superordenador basado en UNIX. Todas las instalaciones standard asociadas con una estación de trabajo UNIX estarán a la disposición del usuario. El sistema operativo utilizado para el servidor, I/O, y las partes del sistema es la versión distribuida de Intel de UNIX (POSIX 1003.1 and XPG3, AT&T System V.3 and 4.3 BSD Reno VFS) desarrollado para el superordenador Paragon XP/S. El Paragon OS presenta una única imagen de sistema al usuario. Esto significa que los usuarios ven el sistema como una única máquina UNIX a pesar del hecho de que el sistema operativo funciona en un conjunto de nodos distribuidos. El sistema operativo en la Parte de Computación es Cougar. Es puerto de Intel de Puma, un sistema operativo ligero para el TFLOPS, basado en el sistema SUNMOS para el Paragon que ha tenido tanto éxito. (SUNMOS y, consecuentemente, Puma, fueron desarrollados por SNL y la Universidad de Nuevo Méjico). Los servicios de sistema y el apoyo para el usuario interactivo son suministrados por el supervisor OS (en este caso, el Parangon OS que funciona en la Parte de Servicio). Todos los accesos a las fuentes de hardware provienen del Q-Kernel, el componente de nivel inferior de Cougar. Por encima del Q-Kernel impone la tendencia de control de proceso (PCT), que funciona en el espacio del usuario y dirige los procesos. En el nivel más alto están las aplicaciones del usuario. Como en la mayoría de los sistemas MPP, el modelo de programación básico en Cougar se basan en el paso del mensaje. Soportará FORTRAN77, FORTRAN90, C y C++. El debugger interactivo y las herramientas de análisis de aplicación entenderán estos lenguajes y los transportarán al código fuente original. Se proporcionará la capacidad de testeo/reset, que se necesita para grandes aplicaciones corran en este ordenador. La anchura de banda I/O será suficiente para comprobar la totalidad de la memoria del sistema en cinco minutos aproximadamente. Fases en la construccion del ASCI Red Diciembre de 1996: El Super Ordenador ASCI Red consigue 1 Trillion de Operaciones por segundos On-line, a tiempo y dentro del presupuesto. Marzo de 1997: Tres cuartos de ASCI Red operativos en Sandia. Junio de 1997: El ASCI Red operativo al completo (mostrado
abajo), consigue 1,3 teraops El sistema IBM de 10 teraOPS "Opción White" se planificó para LLNL durante el año fiscal de 2000. Previendo el futuro, la paralelización de miles de procesadores será ampliado para conseguir una capacidad de computación de 100 teraOPS y más.
Con sus 12,3 billones de operaciones por segundo (o 12,
3 teraflops), ASCI White deja atrás a su inmediata
antecesora, ASCI Blue Pacific -capaz de procesar tan sólo
3,9 teraflops-. Es además 1000 veces más potente que el
ordenador Deep Blue, que en 1997 derrotó al ajedrecista
Gary Kasparov. Para hacernos una idea, el ser humano es
capaz de realizar hasta 100.000 operaciones por segundo,
y necesitaría 10 millones de años para conseguir los cálculos
que el superordenador resuelve en un segundo. Tres fases en la construccion del ASC WhiteEl ASCI White se está entregando en tres etapas. La primera, entregada el 7 de junio, consiste en cuatro conmutadores Colony en ocho bloques de conmutadores y todos los 4.096 cables colony para la red internodal de alta velocidad y baja latencia Colony Double-Double.
En Septiembre del 2000 fue trasladado de las instalaciones de IBM en Nueva York al Laboratorio nacional Lawrence Livermore del Departamento de energía de Estados Unidos, para lo cual fueron precisos 28 camiones, que cargarán las 106 toneladas de la máquina (ocupa dos campos de fútbol y su peso equivale al de 17 elefantes adultos).
BLUE GENE El nuevo supercomputador de IBM Hasta hace bien poco, se pensaba que el petaflop sólo se podría conseguir con ordenadores que trabajasen a muy bajas temperaturas, lo que encarece y complica la construcción y funcionamiento de los equipos, pero los responsables de investigación de IBM se han comprometido a conseguirlo con procesadores CMOS que funcionen a temperatura ambiente. En concreto, se quiere hacer con la próxima generación de microprocesadores Power4 que entrará en fase comercial el año que viene. IBM ha presentado un proyecto para construir el mayor supercomputador hasta la fecha, y que supera con mucho cualquiera de los existentes hasta ahora. Su nombre será Blue Gene, y su función principal la de simular el proceso biológico mediante el cual los aminoácidos se transforman en proteínas. El proyecto durará cinco años y se invertirán unos 100 millones de dólares. Este proceso químico se produce continuamente en los seres vivos, pero para ser simulado en un computador se necesitará que Blue Gene sea 500 veces más rápido que los supercomputadores actuales. Entre las medidas que tomarán los ingenieros de los laboratorios Watson de IBM se encuentra reducir la arquitectura RISC de los supercomputadores actuales desde 200 a tan solo 57 instrucciones. Si a esto se le une el hecho de que integrarán 32 procesadores en cada chip, que cada placa base de Blue Gene tendrá 64 de estos chips, y que se construirán 64 torres con 8 placas cada una, el resultado es que este nuevo computador tendrá más de un millón de microprocesadores, en un espacio físico de 150 metros cuadrados y dos metros de altura. » El
Multiprocesador Cray T3ETM
» 1. Introduccion
» 2.
El Cray T3E
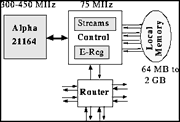
Cada nodo contiene un procesador Alpha 21164,el sistema de control del chip, memoria local, y un router de red(ver Figura 1).La logica de control del chip funciona a 75 MHz, y la velocidad del procesador es multiple (300 MHz para el Cray T3E, 450 MHz para el Cray T3E-900). Los enlaces toroidales le dota de un ancho de banda bruto de 600MB/por segundo en cada dirección, que se queda en un rango de 100 a 480MB/por segundo debido a que debe soportar un protocolo, dependiendo del tipo de trafico. Las I/O están basadas en el canal GigaRingTM, con un ancho de banda sostenible de 267MB/por segundo de E/S para todos los cuatro procesadores. El microprocesador Alpha 21164 es capaz de ejecutar 4 instrucciones por ciclo de reloj, de los cuales una debe ser una suma en punto flotante y otro debe ser una multiplicación en punto flotante, consiguiendo un rendimiento de pico de 600MFLOPS por procesador a 300 MHz y 900MFLOPS por procesador a 450 MHz. Hay cachés de dos nivels en cada chip: 8KB de cachés de primer nivel para datos e instrucciones (8KB para cada una) y un segundo nivel de caché que está unificada de 96KB. Solo la memoria local tiene caché. Estas cachés tienen coherencia con la memoria local gracias a un mapa de memoria externo, cuyos filtros de memoria son referenciados desde nodos remotos y comprueban las cachés del chip cuando es necesario invalidar lineas o borrar datos.
La memoria local está formada por 4 chips de control de memoria, que contrloan 8 bancos de memoria física DRAM. Los caminos entre el chip de control y los controladores de memoria dan una velocidad máxima de transferencia de 32 bits por canal por cada ciclo de reloj del sistema, una velocidad máxima de 4 x 4B x 75 MHz = 1.2GB/por segundo. El bus del procesador de 128 bits también tiene una velocidad de pico de 1.2GB/por segundo, pero solo puede sostener un máximo del 80% (960MB por segundo). El ancho de banda de la memoria local es aumentada por un grupo de buffers.Estos buffers detectan automáticamente automaticamente las referencias a multiples flujos de datos, y realiza una prebuscada de lineas caché en cada flujo de datos. No hay caché en los nodos de un Cray T3E, pero los buffers de cada flujo de datos pueden lograr un gran rendimiento en códigos de aplicaciones cientificas. Los nodos del Cray T3E aumentan el interface del
microprocesador Alpha 21164 con un gran número de
registros externos (E-registers) gestionados de
forma explicita (512 de usuario mas 128 de sistema).
Todas las comunicaciones remotas y sincronizaciones son
efectuadas entre estos registro y la memoria. Ellos
permiten un gran número de peticiones especiales para la
disminución de la latencia. » 3. El Hardware para la minimización de la latencia En los últimos 30 años la manera de resolver el problema de la latencia de las memorias se ha ido solucionando por los ingenieros de arquitectura de computadores mediante el empleo de jerarquías de memorias aumentando la complejidad de estas y utilizando mecanismos que redujesen la latencia para determinados modelos de acceso, los desarrolladores de compiladores han aumentado la profundidad con la que los segmentos de código son evaluados para mejorar la disminución de latencia, los desarrolladores de aplicaciones han vuelto a algoritmos que explotan con mayor eficiencia la localidad de los datos. Mientras el progreso experimentado por los microprocesadores ha sido de varios ordenes de magnitud frente a la solución ante las latencias. Tabla 1: Progreso de la latencia en las
memorias.
Cada uno de estos sistemas introdujeron nuevas técnicas para reducir efectivamente la latencia de las memorias. El CDC 6600 y el 7600 desacoplan las cargas y almacenamientos gracias a varias unidades funcionales con pipeline. Cray® 1 empleó registros vectoriales y un sistema de memoria pipeline. Cray X-MPTM añadió un hardware gather/scatter a las soluciones tomadas en el diseño del Cray-1 para facilitar los modelos de acceso irregular a memorias. El Silicon Graphics POWER CHALLENGE empeó una caché en la placa de 4MB que podía secuenciar operaciones con la memoria efectivamente en banda ancha. El Cray T3E tiene una memoria caché más pequeña pero añade las siguientes soluciones: buffers para cada flujo de datos para el acceso local a memoria y los registros externos (E-registers) para acceso a datos que deben pasar evitando la caché. » 3.1.
cachés de datos Cada procesador del Cray T3E contiene 8KB de caché de primer nivel directamente-mapeada(Dcache), 8KB de caché de instruciones, y 96KB de caché asociativa sendaria de tres vías(Scache) que es usada tanto para datos como para instrucciones. La Scache tiene una política de remplazamiento aleatorio. La velocidad de pico en la transferencia de datos para el acceso a una Dcache y una Scache access se puede ver en la Tabla 2. Esta velocidad corresponde a la máxima velocidad de ejecución de instrucciones de dos cargas por CP o un almacenamiento por CP. La velocidad de pico alcanzable para las cargas en punto flotante, pero es peor en las cargas de enteros debido a limitaciones del microprocesador. Tabla 2: Velocidad de pico
en la transferencia de datos en un Cray T3E-900.
» 3.2.
Buffers de flujo de datos » 3.2.1. Descripción El chip de control de nodo en Cray T3E contiene un grupo de seis buffers de flujo de datos, cada uno de ellos está formado por dos buffers de 64-bytes. Para cada flujo activo de datos, estos buffers realizan la prebusqueda de las dos siguientes lineas cachés. Así pues los buffers pueden tomar 12 lineas caché, 2 por cada uno de los seis. Junto con la función de reducir la latencia también combina la función de pedir las páginas de la DRAM, los buffers también dan un mayor ancho de banda a la memoria local que las cargas desde cache sin buffers. We conducted a series of measurements of simple load/store sequences from local memory in order to assess these effects. En la Tabla 3 podemos ver unas medidas realizadas en la carga y almacenamiento de uno o varios vectores muy largos de datos desde o a una memoria local. Tabla 3: Medida del ancho de
banda de la memoria local en el Cray T3E-900.
Como hemos mencionado en la Sección
2, todas las comunicaciones remotas y las
sincronizaciones en un Cray T3E están hechas a través
de los E-registers y la memoria.Los E-registers
proporcionan dos beneficios principales un mecanismo más
convencional de carga/almacenamiento para acceder a la
memoria global (extendiendo la dirección proporcionada
por el microprocesador para poder direccionar una memoria
muy grande) y incrementar fuertemente el grado de
pipeline para la memoria global. » 3.3.1. Descripción Los E-registers emplean un mecanismo de traducción de direcciones novedoso. El microprocesador implementa un espacio de memoria con caché y un espacio de E/S sin caché, distinguidos por el bit más significativo de la dirección física. La memoria local carga y almacena usando la caché. La traducción de direcciones se hace en el procesador de la forma usual. Hay dos funciones principales realizqadas por los registros externos (E-registers):
La carga/almacenamiento directa es usada para almacenar operandos dentro de los E-registers y almacenar resultados desde los E-registers. Las operaciones con la memoria global son usadas para transferir datos a/desde la memoria global (la remota y la local). Las operaciones de lectura escritura de la memoria a los E-registers son llamadas "Gets and Puts". La traducción de direcciones de Virtual-a-físicase realiza fuera del procesador en la lógica de sistema. El acceso a los E-registers está sincronizado implicitamente por un grupo de flags de estado, uno por E-register. Una operacion Get marca el E-register(os) objetivo como vacío antes de que los datospedidos lleguen de la memoria, en ese momento son marcados como llenos. Como se dispone de un gran número de E-registers (512 de usuario + 128 de sistema), Gets and Puts pueden ser realizadas de una forma pipeline muy grande. El interface procesador-bus permite que se puedan realizar hasta 4 comandos Get o Put propiamente alineados para ser ejecutados en dos ciclos de transacción del bus. El ancho de banda proporcionado por una operación de este tipo es mucho mayor que el ancho de banda sostenible y de este modo el procesador no es un cuello de botella. Los datos en una transferencia memoria-a-memoria usando E-registers no cruzan el bus del porcesador. Cuando una operación utiliza un E-register para la transferencia de datos desde/hasta la memoria local la caché no es utilizada (los datos saltan la caché).Los accesos a memoria sin utlizar la caché son preferidos para la copia de bloques de datos que son demasiado grandes como para entrar en las lineas caché. La Tabla 5 representa los resultados para un solo procesador en un sistema Cray T3E-900. Tabla 5: Comparación de
operaciones de movimiento de datos locales con y sin usar
la caché.
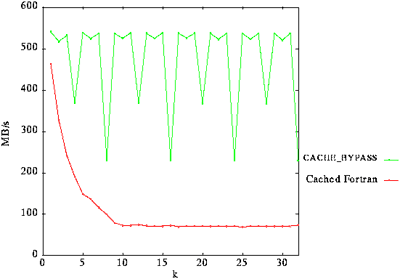
La Figura 2 compara el ancho de banda de una operación y(1:n) = x(1:n:k) para k diferentes flujos de datos usando la directiva de programación en ensamblador "CACHE_BYPASS" para utilizar el acceso a través de E-registers y el ancho de banda logrado con una aplicación programada en Fortran utilizando el acceso a través de caché.
ORIGIN2000
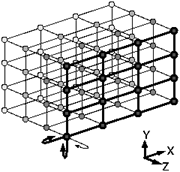
» 1. Introduccion Silicon Graphics y Cray Research desarrollan una arquitectura de informática de alto-rendimiento que será el estándar para la industria en el siglo próximo. Tal como escalabilidad, multiprocesamiento, memoria compartida, o S2MP, esta nueva arquitectura le dará la posibilidad a los clientes de comprar un supercomputador con pocos procesadores y el poder de ir agregando los procesadores a medida que el usuario pueda ir comprándolos, y así hasta tener un supercomputador muy poderoso de cómputo masivo. La serie SGI Origin2000TM de supercomputadores escalables es la primera generación de productos de la compañía con esta nueva arquitectura. En la actualidad SGI ya vende el Origin3800 (foto superior). » 1. Arquitectura del Origin 2000 Una vista ampliada de un sistema "deskside
Origin2000" se muestra en la siguiente figura:
Una vista trasera del chasis del "deskside",
mostrando la localización de las "Node boards"
y las "XIO board":
Figura 2:vista frontal puede verse en grande haciendo clic en ella. La siguiente figura muestra un diagrama de bloques de un sistema básico Origin2000 con un solo nodo conectado a las interconexiones XIO y la CrayLink.
Figura 3:diagrama de bloques de un sistema básico Origin2000, (hacer clic para ver). » 2. Componentes del
Origin 2000 Un sistema Origin2000 tiene los siguientes componentes:
» 2.1. El Procesador La Origin2000 usa el MIPS R1000, un procesador
superescalar de alto rendimiento que soporta planificación
dinámica. Algunos atributos importantes del R1000 son su
largo espacio de direcciones de memoria, junto con una
capacidad para un pesado solapado "overlapping"
de las transacciones de memoria por encima de doce en la
Origin2000.
Figura 4:Evolución que tendrá el procesador MIPS en el Origin2000, (hacer clic para ver). » 2.2.Memoria Cada nodo tablero añadido a la Origin2000 está
provisto de memoria de acceso independientemente, y cada
nodo es capaz de soportar más de 4 GB de memoria. Se
pueden configurar en un sistema por encima de 64 nodos,
lo cual implica un máximo de capacidad de memoria de 256
GB. » 2.3.Controladores de E/S El Origin2000 soporta gran un número de interfaces de
E/S de alta velocidad, incluyendo Ultra Fast, Wide SCSI,
Fibrechannel, 100BASE-Tx, ATM y HIPPI-Serial.
Internamente, estos controladores son añadidos por medio
de trajetas XIO, las cuales tienen un bus embebido PCI-32
o PCI-64. Así, en la Origin2000 el rendimiento de E/S es
añadido un bus a la vez. » 2.4.HUB Este ASIC es el controlador de memorias compartida distribuída. Es responsable de proveer a todos los procesadores y dispositivos de E/S de un acceso transparente a toda la memoria distribuida de una modo que haya coherencia caché. » 2.5.Directorio Memoria Esta memoria complementaria es controlada por el Hub. El directorio mantiene información acerca del estado del caché de toda la memoria dentro de su nodo. Esta información del estado es usada para proveer coherencia de caché escalable, y migrar los datos a un nodo que los accesa más frecuentemente que el nodo actual. » 2.6.Interconexión CrayLink Esta es un grupo de enlaces de muy alta velocidad y routers que son responsables de tratar juntos al conjunto de hubs que componen al sistema. Los atributos importantes de la interconexión CrayLink son su baja latencia, ancho de banda escalable, modularidad y tolerancia a fallos. » 2.7.XIO y Crossbow Estos son los interfaces internas de E/S originadas en cada Hub y terminando sobre el controlador de E/S objetivo. XIO usa la misma tecnología de enlace físico que la interconexión CrayLink, pero usa un protocolo optimizado de tráfico de E/S. El ASIC Crossbow es un chip de enrutamiento crossbar responsable de conectar dos nodos hasta con seis controladores. » 3.Arquitectura del Origin2000 En el sistema Origin2000 se localizan los XBOWs en el plano medio o "midplane" de un módulo de la Origin, como muestra la próxima figura. Hay dos XBOWs en cada módulo, así se proveen conexiones de hasta 12 tarjetas XIO y cuatro "node boards". Los dispositivos de E/S están enlazados a un XBOW ya que pueden ser activados sólo si el XBOW está en por lo menos un nodo, así las conexiones desde un "node board" a XBOWs están entrelazadas. Esto es, que los nodos 1 y 3 se conectan al primero XBOW, y los nodos 2 y 4 al segundo. Esto permite que las 12 ranuras de XIO en un módulo se activen cuando por lo menos dos "node boards" sean instaladas. Estas conexiones son las que van desde XBOW al "PCI Adapter" y las que van del desde los "Node Boards" a los XBOW. Porque el máximo número de procesadores y tarjetas E/S en un módulo tiene que ser ocho procesadores (en cuatro "node boards") y 12 tarjetas XIO, esta construcción de la Origin2000 se refiere al modulo 8P12.
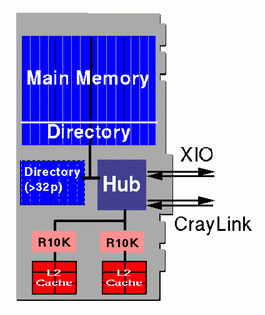
Figura 5:Arquitectura del Origin2000, (hacer clic para ver). Cada módulo 8P 12 también contiene dos tablas de enrutadores, cada una conecta a dos nodos; no hay entrelazado en este caso. Los rastros en el plano medio o "midplane" provee estas conexiones, tan satisfactorias como una conexión entre dos enrutadores; mostradas por las flechas que conectan a los enrutadores con ellos "node boards". Así, un módulo contiene un par de nodos, un bloque de enrutadores construidos, y los sistemas grandes se pueden construir fácilmente conectando múltiples módulos. Las conexiones de los enrutadores con cada módulo para manipularlos se realiza por uniones de cables a conectores en el borde de las "router boards"; éstas son las flechas que van del "router board" hacia la izquierda. » 3.1Tarjeta de nodo "Node board" El sistema Origin comienza con un "node board". Abajo, en el lado izquierdo de la figura, es un esquema de un "node board" de la Origin2000; un dibujo de la "node board" se muestra en el lado derecho:
Figura 5:Node board del Origin2000. Cada nodo contiene uno o dos procesadores R10000. En el sistema Origin2000, los "node boards" están disponible en dos configuraciones:
Todas las "node boards" en el sistema deben tener la misma configuración. Cada procesador y su cache secundaria son empaquetados en un llamado "subassembly" un módulo de la memoria de línea horizontal (HIMM). Dos HIMMs se muestran al fondo del "node board" al borde del dibujo. En general, cada "node board" viene con dos procesadores instalados, pero es posible comenzar con un sistema de 180 MHZ con un solo procesador en el primer "node board"; después de esto, todos los "node boards" vendrán con dos procesadores. En los sistemas de 195 MHz, todo los "node boards" tienen dos procesadores instalados. Además de los procesadores, el "node board" tiene 16 "sockets" de memoria. Los módulos de la memoria son instalados en pares, y así se le da el nombre de módulos duales de la memoria "inline" (DIMMs). Cada par de DIMM representa un banco de memoria. Ocho (8) pares de memorias DIMM pueden ser instalados en una "node board". Estos pares de DIMM vienen en tres tamaños: 64 MB, 128 MB y 512 MB. Por lo menos se debe instalar un par de DIMMs para que un "node board" pueda ser configurable con 64 MB a 4 GB de memoria. Para soportar un ancho de banda alto, los sistemas de la memoria son entrelazados en direcciones de las líneas caché; los accesos secundarios a diferentes niveles permite soportar un ancho de banda completo del sistema de memoria. El subsistema de memoria es bastante rápido para las cuatro formas de entrelazarse y puede proveer el ancho de banda de la memoria, así no necesariamente hay que llenar más de un banco para alcanzar el máximo de velocidad de ejecución. Puesto que el sistema Origin pueden escalar a un número grande de nodos, se requeriría en cada memoria principal DIMM dejar al sistema una cantidad significante de información del directorio. De manera de no sobrecargar los sistemas más pequeños con el "gasto" de memoria del directorio, la memoria principal DIMMs provee sólo almacenamiento del directorio para sistemas hasta de 16 nodos (esto es, 32 procesadores). Para sistemas más grandes, se instala la memoria de directorio adicional separada del directorio DIMMs. El componente final de la "node board" es el cubo. El cubo controla el acceso de los procesadores a la memoria y al I/ O. El cubo tiene una conexión directa, llamada bus SysAD, a la memoria principal en la "node board". Esta conexión provee un ancho de banda de memoria bruta de 780 MB/ s (720 MB/ s en una configuración de 180 MHz ) para los dos R10000s en el "node board". En la práctica, de cualquier modo, no se puede transferir a todos los buses en un ciclo, así que el ancho de banda efectivo es igual 600 MB/s. El Acceso a la memoria remota es por una conexión separada llamada interconexión CrayLink. Esta interconección bidireccional conecta a un router o a otro cubo. Es bidireccional y tiene un ancho de banda de 780 MB/ s en cada dirección (720 MB/ s en una configuración de 180 MHz) . El ancho de banda efectivo para los programas de usuario no supera esta velocidad, aproximadamente 600 MB/ s en cada dirección, ya que no toda la información enviada por el CrayLink son datos de usuario (se debe implementar un protocolo para las transferencias), requiere una copia de una linea de memoria cache remota, un cubo debe primero envíar 16-bytes un paquete con la dirección del cubo que esta conectado a la memoria remota; esto especifica que línea de caché es designada y donde se necesita se enviar. Entonces, cuando los datos son devueltos, con 128-bytes por línea caché de datos del usuario, otro envía 16-byte como cabeza de dirección (así el cubo receptor puede discernir esta línea de caché de otra). Así, 16+ 128+ 16 se pasa 160 bytes de datos por la interconeción CrayLink para transferir los 128-bytes de la línea cache, así que el ancho de banda en vigor es 780* (128/ 160)= 624 MB/ s en cada dirección (576 MB/ s en cada dirección para la configuración de 180 MHz). El cubo también controla el acceso a los dispositivos E/S por un canal llamado XIO. Eléctricamente, esta conexión es lo mismo que el CrayLink, pero se usan protocolos diferentes en la comunicación. El ancho de banda es el mismo que con el CrayLink. Los enrutadores dejan que los cubos múltiples se conecten el uno al otro para comunicar via CrayLink. » 3.2 Memoria compartida Para entender cómo trabaja la arquitectura del Origin 2000, el multiprocesador de memoria compartida escalable S2MP, debemos primero ver cómo están construidos y como se conectan los bloques de un sistema Origin. Esto se refleja en la figura siguiente:
Figura 6:Conexión de los bloques de un sistema Origin (hacer clic para ver). La representación del sistema Origin anterior tiene de rango de 2 a 16 procesadores. Comenzamos considerando el sistema de dos procesador en la esquina superior izquierda. Esta es una Origin2000 con un sólo nodo. Consta de uno o dos procesadores, memoria, y un dispositivo llamado cubo. El cubo es el fragmento de hardware que lleva a cabo los deberes del bus de rendimiento en un sistema basado en bus;es decir, este administra cada acceso a los procesadores y a la memoria y a los dispositivos E/S. Esto se aplica a los accesos que son locales al nodo que contiene los procesadores, también como aquellos que debe satisfacer remotamente en los sistemas multinodos. Los sistemas del Origin más pequeños constan de un solo nodo. Los Sistemas más grandes son construidos por la conexión de múltiples nodos. Se muestra en el medio de la figura un sistema de dos nodos. Ya que la información fluye en y fuera de un nodo se controla por el cubo, conectar dos nodos significan conectar sus cubos. En un sistema de dos nodos esto simplemente significa hacer un alambrado entre los dos cubos. El ancho de banda de la memoria local en un sistema de dos nodos es el doble a un sistema de un solo nodo: el cubo en cada uno de los dos nodos puede acceder su memoria local independientemente del otro. Accesar la memoria en el nodo remoto es un poco más costoso que acceder a la memoria local ya que requiere ser manejada por ambos cubos. Un cubo determina si un requerimiento es local o remoto basado en la dirección física de los datos accedidos. Cuando hay más de dos nodos en un sistema, sus cubos no pueden ser simplemente interconectados. En este caso se requiere añadir hardware para controlar el flujo de información entre los múltiples cubos. El hardware usado para controlar esto en los sistemas Origen se llama enrutador "router" . Un enrutador tiene seis puertos, así puede ser conectados a seis cubos a un router (ver arriba). En la esquina superior de la figura, se aprecia un sistema de cuatro nodos, esto es equivalente a ocho procesador. Esto se construye de dos bloques de enrutadores de dos nodos. Ya que un enrutador tiene seis puertos, es posible conectar los cuatro nodos a sólo un enrutador, y se puede usar esta configuración de un sólo enrutador para sistemas pequeños. Esto es un caso especial, y en general se usa la implementación de dos enrutadores ya que es conveniente para escalar a sistemas más grandes. La cosa importante aquí está en que el hardware permite distribuir físicamente la memoria del sistema a ser compartido, lo mismo que en un sistema basado en buses, pero cada cubo se conecta a su propia memoria local, el ancho de banda de la memoria es proporcional al número de nodos. Como resultado, no hay ningún límite inherente al número de procesadores que se pueden usar efectivamente en el sistema. Además, la dimensionalidad de la configuración de los enrutadores crece como los sistemas se ponen más grande, el ancho de banda total de los enrutadores también crece con el sistema. Así, estos sistemas pueden ser escalables sin ningún temor que las conexiones de los enrutadores lleguen a ser un problema. Para permitir esta escalabilidad, hay que sacrificar una característica muy buena de los sistemas de memoria compartida basados en buses el tiempo de acceso a la memoria es uniformemente más largo: esto varía dependiendo de que lo lejos que esté la memoria accedida del sistema. Los dos procesadores en cada nodo tienen acceso rápidamente por su cubo a su memoria local. Acceder a la memoria remota por un cubo adicional agrega un incrementado de tiempo extra, como hacer cada enrutador para que los datos viajen por él. Pero la combinación de varios factores hacen que los accesos a la memoria no sean uniformes (NUMA) en cuanto al tiempos:
La arquitectura del sistema Origin2000, entonces,
proporciona hardware de memoria compartido sin las
limitaciones de los diseños tradicionales basados en
buses. » 4. Lo que hace que el sistema Origin2000 sea diferente Las siguientes caracterísiticas hacen diferente al Origin2000 de arquitecturas previas:
» 4.1. Escalabilidad El Origin2000 es fácilmente escalable al enlazar nodos juntos sobre una malla de interconexión, el ancho de banda del sistema se escala linealmente con un incremento en el número de procesadores, y la malla de intercambio asociada. Esto significa que el Origin2000 puede tener un bajo coste de entrada, ya que usted puede construir un sistema ascendente de una configuración inicialmente pequeña Origin2000. En contraste, los sistemas tradicionales basados en bus son solo escalables en la cantidad de su procesamiento y poder de E/S. La interconexión Everest es el E-bus, el cual tine un ancho de banda fijo y es el mismo tamaño desde el nivel de entrada al "high-end". » 4.2. Modularidad Un sistema consta de nodos estándar de procesamiento. Cada nodo contiene procesador(es), memoria, un directorio para coherencia de caché, una interfaz de E/S y una interconexión del sistema. Los "Node boards" son colocados en uno de los siguientes tres tipos de módulos del sistema: nivel de entrada "entry-level", "deskside" o "rack". Los sistemas tradicionales basados en bus no son modulares; hay un número fijo de slots en cada "deskside" o sistema "rack", y este número no puede ser cambiado. » 4.3.Interconexión del sistemas La Origin2000 usa una malla de interconexiones y "crossbars". La malla de interconexiones es una red de enlaces alojados-dinámicamente conectados por intercambio o "switched-conected" que añaden nodos a otros. Los "Crossbars" son parte de la malla de interconexión, y están localizados dentro de varios de los ASICs -- el "Crossbow", el Router y el Hub. Los "Crossbars" enlazan dinámicamente puertos de entrada ASIC con sus puertos de salida. En los sistemas tradicionales basados en bus, los procesadores accesan la memoria y las interfaces de E/S sobre un bus de memoria compartida que tiene un tamaño fijo y un ancho de banda fijo. » 4.4 Memoria compartida distribuída ("Distributed shared-Memory" DSM) y E/S La memoria de la Origin2000 está dispersa físicamente a través del sistema para rápido acceso por los procesadores. El hardware de migración de páginas mueve los datos a la memoria más cercana a un procesador que la usa frecuentemente. Este esquema de migración de páginas reduce la latencia de memoria el tiempo que toma recuperar los datos desde la memoria. Aunque la memoria principal es distribuida, esta es universalmente accesible y compartida entre todos los procesadores en el sistema. Similarmente, los dispositivos de E/S son distribuidos entre los nodos, y cada dispositivo es accesible a cada procesador en el sistema. Los sistemas tradicionales basados en bus tienen memoria compartida, pero su memoria es concentrada, no distribuída, y ellos no distribuyen E/S. Todos los accesos de E/S, y aquellos accesos de memoria no satisfechos por la caché, incurren en una latencia extra cuando atraviesan el bus. La memoria del Origin2000 está localizada en un solo espacio de direcciones compartidas. La memoria dentro de este espeacio es distribuída entre todos los procesadores, y es accesible sobre la malla de interconexión. Esto le diferencia de un sistema "CHALLENGE-class", en el cual la memoria está colocada centralmente y es accesible unicamente desde un sólo bus compartido. Al distribuir la memoria del Origin2000 entre los procesadores la latencia de memoria se reduce: acceder a la memoria cercana a un procesador toma menos tiempo que acceder a la memoria remota. Aunque distribuida físicamente, la memoria principal está disponible a todos los procesadores. Los dispositivos de E/S también son distribuídos dentro de espacio de direcciones compartido; cada dispositivo de E/S es accesible universalmente a través del sistema. » 4.5 Jerarquía de Memoria del Origin2000 La Memoria en la Origin2000 está organizada dentro de la siguiente jerarquía:
Figura 6:Jerarquía memorias de un sistema Origin2000 (hacer clic para ver).
Esto permite que los 12 slots XIO en un modulo se activen cuando tan poco como dos "node boards" sean instaladas. Estas conexiones son las flechas verdes en la figura. Porque el máximo número de procesadores y tarjetas I/O en un módulo tiene que ser ocho procesadores (en cuatro node boards) y 12 tarjetas XIO, esta construcción de la Origin2000 se le refiera el modulo 8P12.
» 5. Microprocesador R10000 En esta sección se describe la arquitectura del microprocesador R10000. » 5.1 Arquitectura Superescalar de Cuatro-vías El R10000 es un microprocesador de "MIPS Technologies". Está diseñado para resolver muchos de los cuellos de botella comunes en el rendimiento en las implementaciones de los microprocesadores existentes. En la Origin2000, el R10000 corre entre 195 MHz o 180 MHz. El R10000 es un procesador superescalar RISC de cuatro-vías. Este puede buscar ("fetch") y decodificar cuatro instrucciones por ciclo al ser ejecutado sobre sus cinco unidades independientes de ejecución encauzadas: una unidad no bloqueda de carga/almacenamiento, dos ALU's de 64-bit para enteros, un sumador de punto flotante encauzado de 32-/64-bit y un multiplicador de punto flotante encauzado de 32-/64-bit. Las ALU's enteras son asimétricas. Aunque ambas ejecutan sumas, restas y operaciones lógicas la ALU 1 maneja desplazamientos ("shifts"), bifurcaciones condicionales y instrucciones "move" condicionales, y la ALU 2 es responsable de las multiplicaciones y divisiones enteras. De forma similar, las instrucciones son partidas entre las unidades en punto flotante. El sumador de punto flotante es responsable por las operaciones de sumas, restas, valor absoluto, negado, redondeo, truncado, techo, piso, conversiones, y comparaciones, y el multiplicador de punto flotante lleva a cabo multiplicación, división, recíproco, raíz cuadrada, raíz cuadrada recíproca e instrucciones de "move" condicional. Las dos pueden ser encadenadas juntas para ejecutar operaciones de multiplicar-sumar ("multiply-add") y multiplicar-restar ("multiply-subtract"). » 5.2 Conjunto de instrucciones de la arquitectura MIPS IV El R10000 implementa el conjunto de instrucciones de la arquitectura MIPS IV "instruction set architecture" (ISA). Este es un super conjunto del conjunto de instrucciones previo MIPS I, II, y III , de manera que los programas compilados para estas "ISAs" son compatibles-binarios con el R10000. El MIPS IV ISA también es usado en los R8000, así los programas R8000 son también compatibles-binarios con el R10000. En adición a las instrucciones de 32 y 64 bits
contenidas en los previos MIPS ISAs, IPS IV también
incluye instrucciones de suma-multiplicación en punto
flotante (madd), recíproco, raíz cuadrada recíproca,
carga y almacenamiento indexadas ("indexed loads and
stores"), instrucciones de prebúsqueda ("prefetch
instructions"), y "moves" condicionales.
Aunque las operaciones de carga y almacenamiento de las
MIPS I, II, y III permiten direcciones a ser construidas
como un desplazamiento constante en tiempo compilación
desde un registro base, carga y almacenamiento indexadas
permiten al desplazamiento ser un valor en tiempo de
ejecución contenido en un registro entero; estas
instrucciones permiten reducir el número de incrementos
de direccionamientos dentro de los lazos. Las
instrucciones prebuscadas ("prefetch instructions")
permiten solicitar datos para ser movidos a la caché
antes de que se necesiten, así se elimina gran parte de
la latencia de una pérdida de caché. La instrucción
"move" condicional puede ser usada para
reemplazar bifurcaciones dentro de lazos, y así permitir
firmemente, ser generado código superescalar para esos
lazos. MIPS IV ISA especifica la disponibilidad de 32
registros enteros y 32 registros en punto flotante. » 6. El sistema operativo El sistema operativo de la origin 2000 es IRIX Versión 6.4, y se le puede instalar el software necesario para el desarrollo de aplicaciones destacando:
En febrero de 1997, el SGI lanza la nueva versión de IRIX celular, IRIX 6.4 para el Origin, Onyx2 y OCTANO. Este lanzamiento de IRIX incluye modificaciones para arreglar los "bug" y otras características para las nuevas plataformas existentes de Origin y Onyx2 así como también para apoyar las nuevas estaciones de trabajo OCTANO. IRIX 6.4 es específico para los sistemas Origin, Onyx2, y OCTANO, y no se utiliza en ninguna otra plataforma SGI. TOP 20 DE LAS MÁQUINAS SUPERCOMPUTADORAS MÁS POTENTES
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||





















{kind=link}